Using Jenkins for Disparate Feedback on GitHub
| This is a guest post by Ben Patterson, Engineering Manager at edX. |
Picking a pear from a basket is straightforward when you can hold it in your hand, feel its weight, perhaps give a gentle squeeze, observe its color and look more closely at any bruises. If the only information we had was a photograph from one angle, we’d have to do some educated guessing. 
As developers, we don’t get a photograph; we get a green checkmark or a red x. We use that to decide whether or not we need to switch gears and go back to a pull request we submitted recently. At edX, we take advantage of some Jenkins features that could give us more granularity on GitHub pull requests, and make that decision less of a guessing game.

Multiple contexts reporting back when they’re available
Pull requests on our platform are evaluated from several angles: static code analysis including linting and security audits, javascript unit tests, python unit tests, acceptance tests and accessibility tests. Using an elixir of plugins, including the GitHub Pull Request Builder Plugin, we put more direct feedback into the hands of the contributor so s/he can quickly decide how much digging is going to be needed.
For example, if I made adjustments to my branch and know more requirements are coming, then I may not be as worried about passing the linter; however, if my unit tests have failed, I likely have a problem I need to address regardless of when the new requirements arrive. Timing is important as well. Splitting out the contexts means we can run tests in parallel and report results faster.
Developers can re-run specific contexts
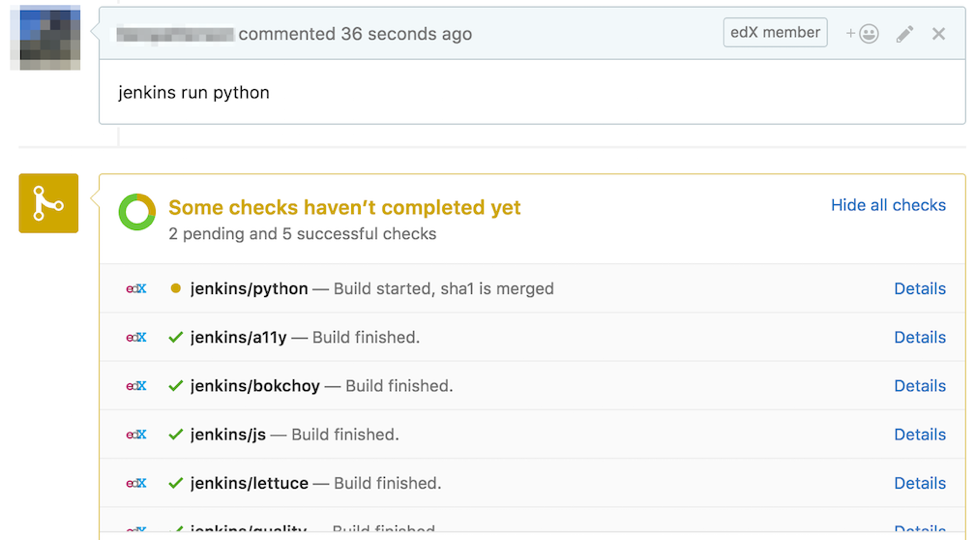
Occasionally the feedback mechanism fails. It is oftentimes a flaky condition in a test or in test setup. (Solving flakiness is a different discussion I’m sidestepping. Accept the fact that the system fails for purposes of this blog entry.) Engineers are armed with the power of re-running specific contexts, also available through the PR plugin. A developer can say “jenkins run bokchoy” to re-run the acceptance tests, for example. A developer can also re-run everything with “jenkins run all”. These phrases are set through the GitHub Pull Request Builder configuration.
More granular data is easier to find for our Tools team
Splitting the contexts has also given us important data points for our Tools team to help in highlighting things like flaky tests, time to feedback and other metrics that help the org prioritize what’s important. We use this with a log aggregator (in our case, Splunk) to produce valuable reports such as this one.
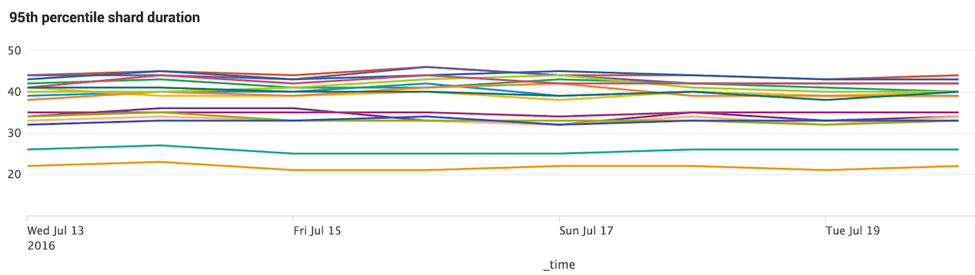
I could go on! The short answer here is we have an intuitive way of divvying up our tests, not only for optimizing the overall amount of time it takes to get build results, but also to make the experience more user-friendly to developers.
|
Ben will be presenting more on this topic at
Jenkins World in September,
register with the code |